
今天我們進入 ML 專案的第三個步驟——建立模型(Build the Model)。
為了訓練出一個可以實際部署上線並解決商業需求的模型,機器學習專案往往會經歷一個反覆迭代的過程,包括以下步驟
獲得初步數據集,如同我們在 [Day 5] Step 2. 蒐集和準備資料(Collect and Prepare Data) 介紹的,需要確保數據具有代表性,並且能夠解決目標問題。
一旦數據準備完畢,接下來的步驟是選擇適合的模型並開始訓練。而在訓練之前,通常會建立一個 baseline model 來作為參考,以助於評估新模型的性能。
建立 baseline model 的方法
根據資料種類而有不同選擇
要如何開始一個模型訓練呢?Andrew Ng 給了幾個起步的建議:
建立 baseline 模型後,除了考慮模型的表現和可行性以外,也要考慮到模型的部署限制。舉例來說,模型可能需要部署在雲端、本地、用戶的電腦或手機上,因此必須考量運算效能和模型大小等因素。
分析模型在哪類的數據表現比較差,哪類數據的表現較好。錯誤分析有助於找出模型表現較差的地方,並且要特別關注對於稀有類別和偏斜數據分佈的處理方式。
另外,要瞭解模型在資料集上的表現,可以建立一個如下圖的分析表格,針對模型發生的錯誤進行審核。這個表格呈現一個語音辨識模型發生的錯誤案例,陳列每個數據的 label(真實標籤)、prediction(模型的預測)、以及是否存在環境噪音(例如汽車聲、人物聲)。這樣可以有效分析哪些因素導致了錯誤的預測,進而改善模型的效能。
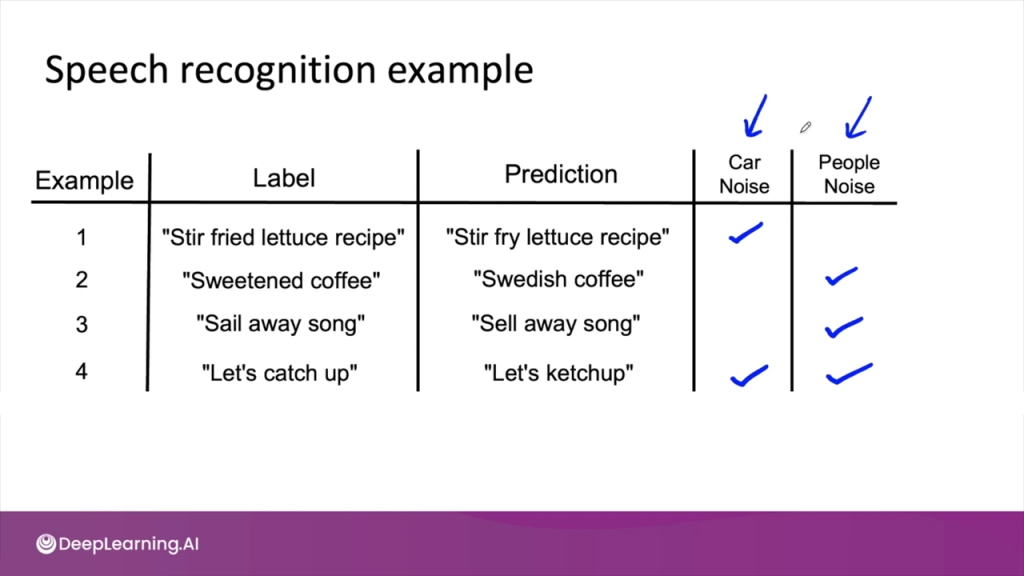
圖片來源:Machine Learning in Production | DeepLearning.AI
如果模型表現不佳,可能需要重新蒐集數據、改善數據品質、重新選擇模型,或是調整模型參數。
在開發模型時,根據訓練表現和訓練過程的階段,會遇到不同的挑戰。
首先,模型需要先在訓練資料集上表現良好,才能進一步評估其在開發資料集和測試資料集上的表現。
當模型在訓練資料集上表現良好後,才能開始對開發資料集和測試資料集進行表現評估。
最後,如同 [Day 4] ML Project Lifecycle 介紹 - Step 1. 定義商業指標(Define the business goal)提過的,一個優秀的模型不僅要滿足機器學習的指標,也要能夠達成達成商業目標。就算能夠模型將模型訓練到誤差極小,也不代表模型能夠解決商業需求中的關鍵問題。
在訓練模型時,我們都會希望模型在資料集上的誤差越小越好。然而,即便誤差極小,有時卻無法反映模型在一些關鍵場景下的表現,而這些場景可能對於商業利益來說是非常重要的。
在某些應用情境下,並非所有案例的重要性相同。例如:
如果只是將所有場景的誤差都平均計算,可能會忽視這些關鍵案例的重要性,導致模型在關鍵應用場景中表現不佳。
模型在特定資料子集(如不同性別、國籍等)上是否公正,這個會直接關係到模型的公平性和商業應用的成敗。舉例來說,在貸款審批模型中,模型需要避免對某些國籍、性別或語言有偏見。同理,在產品推薦系統中,需要謹慎處理不同類型的用戶、零售商和產品,以確保公平性。
Netflix 在運用機器學習技術來優化 Match Cutting 時,發現了兩個主要挑戰。
首先,儘管模型在初步測試中表現良好,但當應用於大規模數據時,擴展性不足,導致處理速度緩慢,無法滿足需求。
其次,雖然模型成功識別了 action matching 的片段,但結果與預期不符,所找到的匹配片段未能實現他們理想中的視覺效果。因此,Netflix 必須重新考慮模型的訓練方法和數據處理流程,以提升效能並達到預期的效果,才能符合商業利益。
今天,我們介紹一些在訓練模型時需要特別考量之處,在業界實作機器學習專案時,除了單純將一個模型的表現提升,我們更要同時考量商業利益以及實際業務場景的運用方式,達到最終的商業目標!
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
如果有任何問題想跟我聊聊,或是想看我分享的其他內容,也歡迎到我的 Instagram(@data.scientist.min) 逛逛!
我們明天見!
